2017-07-05 ~ 2017-07-18
Dynetのインストール
gccはlinuxbrewで入れたものを使う
% which gcc gcc (Homebrew gcc 5.3.0) 5.3.0 Copyright (C) 2015 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Eigen3をインストール
brew install eigen
glibcのバージョン
brew install glibc
> glibc: stable 2.19
> The GNU C Library
リポジトリをクローン
git clone https://github.com/clab/dynet.git
ビルドの準備
cd dynet mkdir build cd build cmake .. -DEIGEN3_INCLUDE_DIR=$HOME/.linuxbrew/include/eigen3/ -DPYTHON=`which python``
ビルド
make -j20 <|| 実行確認 >|sh| ./examples/train_xor # 動いた
c++までは動作を確認した.
-
- -
cd python
python setup.py install
実行
python >> import dynet # ImportError: /lib64/libc.so.6: version `GLIBC_2.14' not found (required by ./_dynet.so)
残念
あとで頑張る
考えられる原因
連続する整数の和
Sum of Consecutive Integers | Aizu Online Judge
整数Nがあたえられる.
2つ以上の連続する整数の組み合わせのうち,
和がN(1<=N<=1000)に等しくなるものの数を求める.
1. 連続する整数,つまり初項1,等差1の等差数列の部分列
2. 2点(左右)が定まれば良いので,全探索できる
//#define _GRIBCXX_DEBUG #include <bits/stdc++.h> # define rep(i, n) for (int i = 0; i < (int)(n); i++) using namespace std; int sum (int l, int r) { return (r*(r+1)-l*(l-1)) / 2; } int main() { int n; while (cin >> n, n) { int l, r; int ans = 0; for (int l=1; l<=n; l++) { for (int r=l+1; r<=n; r++) { int ret = sum(l, r); /* if (ret == n) cout << l << ", " << r << "= " << ret << endl; */ if (ret == n) ans++; } } cout << ans << endl; } return 0; }
Keitai Message
Keitai Message | Aizu Online Judge
つらいやるだけ問題.
1. ヘッドを用意して順次更新
2. 0が入力されたら出力にpushしてヘッドを初期化
//#define _GRIBCXX_DEBUG #include <bits/stdc++.h> # define rep(i, n) for (int i = 0; i < (int)(n); i++) using namespace std; class Keyboard { public: string input, output; vector<vector<char>> keyboard; string make_output(); Keyboard(string input) : input(input) { // IMPORTANT: vector<vector<char>> keyboard; // これをここでやってしまうとメンバ変数とは違う // 形で初期化が行われてしまい外部から参照できなくなる keyboard.resize(10); keyboard[0] = vector<char>({'A'}); keyboard[1] = vector<char>({'.', ',', '!', '?', ' '}); keyboard[2] = vector<char>({'a', 'b', 'c'}); keyboard[3] = vector<char>({'d', 'e', 'f'}); keyboard[4] = vector<char>({'g', 'h', 'i'}); keyboard[5] = vector<char>({'j', 'k', 'l'}); keyboard[6] = vector<char>({'m', 'n', 'o'}); keyboard[7] = vector<char>({'p', 'q', 'r', 's'}); keyboard[8] = vector<char>({'t', 'u', 'v'}); keyboard[9] = vector<char>({'w', 'x', 'y', 'z'}); } }; string Keyboard::make_output() { int curr; int prev = -1; int freq = 0; output = ""; rep (i, input.size()) { curr = (int)input[i] - 48; // ascii code // 一緒 or 初め if (curr == prev || prev == -1) freq++; // 入力確定 if (curr == 0) { if (prev != -1) { freq--; int qindex = keyboard[prev].size(); /* cout << "i, j: " << prev << "," << freq % qindex << endl; */ /* cout << keyboard[prev][freq%qindex] << endl; */ output += keyboard[prev][freq%qindex]; } // 初期化 prev = -1; freq = 0; } else prev = curr; } return output; } int main() { int n; string s; cin >> n; rep (i, n) { cin >> s; Keyboard k = Keyboard(s); cout << k.make_output() << endl; } return 0; }
お姫様のギャンブル
Princess's Gamble | Aizu Online Judge
実際にシミュレーションをする.
分母に0が来ることがあるので0除算の恐れがある.
場合分けを行えば良い.
//#define _GRIBCXX_DEBUG #include <bits/stdc++.h> # define rep(i, n) for (int i = 0; i < (int)(n); i++) using namespace std; int main() { int n, m, f; while (cin >> n >> m >> f, n) { vector<int> x(n); rep (i, n) cin >> x[i]; float sum = 0; rep (i, n) sum += 100.0*x[i]; float ret = sum - ((float)f/100) * sum; int ans = ret / x[m-1]; cout << (ans > 0 ? ans : 0) << endl; } return 0; }
C++で文字列を数値にする
c_strでconst char*に変換するといける
普通はどうするものなのかよくわかっていない
(そもそも文字列->数値な変換が発生すること自体がダメ?)
//#define _GRIBCXX_DEBUG #include <bits/stdc++.h> # define rep(i, n) for (int i = 0; i < (int)(n); i++) using namespace std; int main() { string a = "53"; int i = atoi(a.c_str()); cout << i << endl; return 0; }
Long Short-Term Memory Over Tree Structures
- 論文: https://arxiv.org/abs/1503.04881
- 実装: https://github.com/pfnet/chainer/blob/master/chainer/functions/activation/slstm.py (in chainer)
概要
LSTMの木構造への一般化を考える.
背景
LSTMは線形な系列を入力に受け取る,非常に成果をあげているニューラルネットワークである.
しかし,いくつかのケースでは入力が線形ではなく,なんらかの構造を持っていた方が良さそうなケースというものもある.
代表的なものにstanford nlpの[sentiment treebank](https://nlp.stanford.edu/sentiment/)がある.
これは文を構文解析し,構文木が入力として与えて文の極性を予測するタスクである.
葉ノード(単語に相当する)と内部ノード(フレーズに相当する)に対して極性が人手(?)でアノテーションされている.
[Socher et al.](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pd://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)はRecursive Neural Network(RvNN)・RNTNNを用いてこのタスクを解いた.
RvNNは内部に再帰構造を持っており,木を入力とすることができる一方で,木の深さが深くなると勾配消失が起きてうまく学習できない問題がある.
これは通常のRNNにも見られる問題であり,LSTMはメモリブロックという概念を導入することでこの問題に対処した.
この成果を活かし,RvNNにもLSTMのメモリブロック構造を導入し,より深い構文木が入力されても学習可能なS-LSTM(Structured-LSTM)を提案した.
手法
モデル全体は以下の図のようになっている.

また,各ノードに注目すると以下の図のようになっている.

LSTMと非常によく似た構造であり,差分としてはS-LSTMには忘却ゲートが2つ存在する.
ちなみに,忘却ゲートが2つと言っているが,これは入力される木が2分木であると仮定しているからそうなっているだけであり,n分木の場合は忘却ゲートがn個になる.
著者曰く
> Extension of teh model to handle more children is rather straightforward
である.
ちなみに,なぜ入力が2分木なのかというと,sentiment treebankのデータ構造が2分木であり,Socher et al.と同じ条件で実験しているからである.
入力・セル・重み・入力ゲート・忘却ゲート・出力ゲートについて詳しく見ていく.
忘却ゲートとセル,および重みが2つあることがわかる.
学習はSocher et al.と同じように行う.ロス関数は2通り考えられている.
実験
sentiment treebankを用いて評価実験を行なった.
比較対象はSocher et al.のRvNNとRNTN,,あとNaive BayesとSVM.
RvNNは通常のRecursive Neural NetworkでRNTNはRecursive Neural Tensor Network.
RNTNはテンソルを用いたRvNNの一般化(?)モデルであるらしい.Socher et al.を読んでください.
| MODEL | ROOTS | PHRASES |
|---|---|---|
| NB | 41.0 | 67.2 |
| SVM | 40.7 | 64.3 |
| RvNN | 43.2 | 79.0 |
| RNTN | 45.7 | 80.7 |
| S-LSTM | 48.0 | 81.9 |
S-LSTMが一番良い性能を発揮した.
S-LSTMはRNTNと比較すると学習にかかる時間が短い点もアピールされている(論文を読んでください).
ここからが面白い点だが,著者らはsentiment treebankのアノテーションはあまり現実のデータに則していないことを指摘している.
というのも,sentiment treebankは木のすべてのノードに対してアノテーションを行なっているが,現実のデータにフレーズ単位のアノテーションが付与されているとは考えにくい.
そのため,フレーズ単位のアノテーションが得られていない以下の2つの設定で追加実験をを行なった.
おそらく以下のようなデータが与えられている(赤色がアノテーションされていることを示す).

| MODEL | ROOTS |
|---|---|
| (a) RNTN | 29.1 |
| (a) S--LSTM | 29.1 |
| (b) RNTN | 34.9 |
| (b) S--LSTM | 44.1 |
同じ条件下ではRNTNよりも良い予測性能を発揮していることがわかる.
議論の腰を折りかねない疑問として「本当に入力に構造があった方が良いのか?」というものがある.
通常のLSTMも暗黙的に構造のようなものを学習していて,入力データには明示的な構造は必要ないのではないかという意見も起きうる.
そこで,データに対して特殊な制約を加えて,それらのデータを学習に使った場合と木構造を入力とした場合の予測性能も比較している.
LSTM--LRとLSTM--RRという2つの特殊なデータは,本来木構造を持っていた入力データの枝を張り替えて,構造を壊したものである.
LRは文中の1番左の単語の左側にルートノードを張り,RRは1番右の単語の右側にルートノードを張っていることを示している.
| MODEL | ROOTS |
|---|---|
| (a) S--LSTM--LR | 40.2 |
| (a) S--LSTM--RR | 40.3 |
| (a) S--LSTM | 43.5 |
| (b) S--LSTM--LR | 43.1 |
| (b) S--LSTM--RR | 44.2 |
| (b) S--LSTM | 44.1 |
LRとLLはほぼ同じ性能,もともとの木構造を入力としたものがそれより良い性能を発揮していることがわかる.
この結果から,著者は少なくともいくつかのタスクにおいては入力データの木構造は予測性能に影響を与えると結論付けた.
Research and reviews in question answering system
走り書きです.
- conference CIMTA 2013
- Sanjay and Vaishali
概要
QAのサーベイ. QAは現在のクエリを投入したら適合文書のリストが渡されて,そこから正確な情報をクエリ投入者が探すというパラダイムを超える可能性を持っている.
QAシステムは時間をかけて大変進歩してきたが,まだ幾つかの挑戦的な課題を残している.
- 自然文の質問を理解すること
- 質問タイプの分類
- 適切なクエリ化
- 曖昧性解消
- 意味的類似語の検出
identification of temporal relationship in complex questions
QAシステムの3つのステップ
- 質問解析
- パージング
- 質問分類
- クエリ構築
- 文書解析
- 候補抽出
- 解答特定
解答解析
- 解答候補のランク付け
QAシステムの分類
Linguistic Approach
- tokenization and parsing
- 異なる分野では異なる文法が必要になるなど,可搬性に乏しい
- 適切なKBを作るのは時間がかかる
- knowledge information is organized in the form of production rules, logics, frames, templates(triple relations), ontologies and semantic networks
- tokenization and parsing
Statistical Approach
Pattern Matching Approach
Ling
データベースに問い合わせるための自然言語インターフェース
自然言語文をクエリにする
- BASEBALL
- LUNAR
DIALOG
- ELIZA
- GUS
これらの手法では,データを構造化データベースに格納するため,解答能力に制約がある.
これらの制約を許容して,構造化データベースから得られる情報をもとに推論を行うタイプの質問応答システムが現れた.
STARTはWEBを知識源としている.経験則的な情報を用いてWeb上の情報を知識ベースに格納する.
Rule
Auarc,Carqは経験則にもとづいて質問文中から質問のタイプを分類する語彙的,意味的なヒントを探す.
- who, what, which, where,...
- others
Statistical
Answer finding task(クエリに対応する解答を統計的に探す)に使ってみたところ,パフォーマンスはデータセットの語彙数に依存することがわかった.
IBMが作った質問応答システムでは,Okapi(BM25?)とTREC-9のQAコーパスを使ったクエリの拡張の2つを採用していた.
Statistical methodでは,クエリと文書,もしくは一文との類似度をどのように計算するかがキモになっていて,キーワードの類似度やクエリや文書の長さ,出現単語の語順の類似など,様々な尺度が考えられ適用されている.
Pattern Matching
「Where was Cricket World Cup 2012 held ?」という質問に対して,「where was
現在の質問応答システムの多くは上記のようなパターンをテキストから自動的に学習することが多い(言語学的な知識やオントロジー,言語資源(WordNetなど)を用いる複雑な手法は採用されない傾向がある).
あまり複雑な質問に応答することはできない(パターンが膨大になる)ため,小-中規模の比較的簡単かつ限られた質問をされるような場面で使いやすい.
Surface Pattern based
大量の正規表現を使って解答を抽出する.
正規表現を大量に作成するのは非常に手間のかかる作業であるが,それらによって抽出される解答は非常に精度が高い.
得られた解答の信頼度を定量的に示すためにsurface patternを用いる手法もある.それらは高精度かつ低再現度である.
Template based
slotを埋めていくアプローチ.slotを埋めるタイプの質問応答は音声系の研究で多いと指導教官に教えてもらった記憶がある.
新しいデータが入ってきたとき,新しいテンプレートを作らなくてはそのデータに対応することができない.
Summary
linguistic approachは限定的なドメインをスコープに持つときにきわめて良いパフォーマンスを発揮する. 知識ベースを人でで作るのは分野の専門家が必要であり,手間もかかる. 最近の研究では,Webを知識源とすることによって知識ベースを強化したりオープンドメイン質問応答をしようという試みがある.
Statistical approachは充分な語彙数の大規模なデータ(= データ間が比較可能)が得られているときに良いパフォーマンスを発揮する. Statisticalなアプローチを取るときには,充分な訓練データがなければいけないが,一度適切に学習することができれば複雑な質問に対しても良い解答を生成することができる.
Pattern based approachは言語学的な分析をする代わりにテキストの特徴的な表現を活用する.Pattern basedな手法はその「浅さ」(表面情報しか加味しない点)ゆえに失敗することもあるが,Webをデータ源として活用するための効率的なテクニックでもある.Pattern basedな手法は,言語学的な情報への依存を減少させるだけでなく,不均質なデータをうまく扱える.だが,しばしばこの手法は意味的におかしい解釈や判断を行うことがある)(「浅さ」ゆえに).
これらの基本的なアプローチは,単体ではそれぞれに異なる制約がある.これらの手法を組み合わせることでより精度,再現率の良いシステムを構築する試みもあり,ASQAやIBM Watsonなどが有名.
結び
QAシステムを実装するにあたって,どの技術を用いるべきかは想定される問題のタイプにきわめて強く依存している. 複数のアプローチのハイブリッドが良い結果を出しているが,以前として基本的な手法の研究も重要であり続けるだろう.
Python文法詳解メモ
Python文法詳解という本がある. 読むととてもためになる.自分がおおと思ったものをメモしている.
気になったら実際に読んでみると良いと思います.上記のリンクはオライリーの商品詳解ページを指していますが,このリンクを経由して本書を購入することで私に金銭的な利益が発生することはないので安心してください.
適当な値を要素に持つ配列を作る
こうしてた
[1 for _ in range(N)]
こうできる
[1] * N
罠があります(前者で作るのかな). 後者の書き方でリストを作ると実行時間が劇的に短い.なんでかは考えてみてください.
算術演算
これは
a ** b % c
こっちのほうが高速
pow(a, b, c)
powって第三引数取れたんですね...
リストの展開
def spam(ham, egg): return (ham, egg) a = [1, 2] spam(*a)
辞書の展開
def spam(ham, egg): return (ham, egg) a = {'ham': 1, 'egg': 2} spam(**a)
ちなみに辞書を展開して変数にする(?)ので,キーは文字列でなければなりません(1 = 2みたいなことになってしまう).
要素の分解
a, b, *c = list(range(10))
右辺の要素の数が足りないとき,cは空のリストになる(ただし,a, bは値がないといけないので,以下はエラーになる.
a, b, *c = list(range(1)) #=> Traceback (most recent call last): # File "<stdin>", line 1, in <module> # ValueError: not enough values to unpack (expected at least 2, got 1)
shallow copyとdeep copy
>>> a = [1,2,3] >>> b = a >>> a.append(1) >>> a [1, 2, 3, 1] >>> b [1, 2, 3, 1]
>>> >>> a = [1,2,3] >>> b = a.copy() >>> a.append(1) >>> b [1, 2, 3] >>> a [1, 2, 3, 1]
よく見ると新しくオブジェクト作ってるやつ
>>> a = 1 >>> b = a >>> a += 1 >>> b 1
list.extend(iterable)
>>> a = [1,2,3]
>>> a.extend([1,2,3])
>>> a
[1, 2, 3, 1, 2, 3]
>>> a.extend('spam')
>>> a
[1, 2, 3, 1, 2, 3, 's', 'p', 'a', 'm']
>>>
リストの末尾にイテラブルオブジェクトのすべての要素を追加する.
list.sort(key=int)
>>> a = ['1', '10', '2', 3] >>> a.sort(key=int) >>> a ['1', '2', 3, '10']
なにこれすごい.
str.center(w)
>>> 'a'.center(10) ' a ' >>> 'a'.center(10, '*') '****a*****' >>>
プログラミング演習でつかえそう(内輪ネタ).
辞書内包
>>> {x+y:1 for x in 'abc'
for y in '123'}
{'a3': 1, 'c2': 1, 'c1': 1, 'c3': 1, 'a2': 1, 'b3': 1, 'b2': 1, 'a1': 1, 'b1': 1}
>>>
集合内包
{i for i in range(10)}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>>
set(i for i in range(10))って書いてた.
そういえば,set([i for i in range(10)])って書かなくて良いのも最近知りました.
例外の送出
raise ValueError('不正な値です')
print('不正な値です')ってやってた.
関数アノテーション
>>> def spam(ham: "ハムの枚数") -> int: ... return ham >>> spam(2)
きちんと書くとIDEが良い感じにしてくれるらしい(伝聞).
ラムダ式
>>> f = lambda x, y, z: 1 >>> f(1, 2, 3) 1 >>>
続パタの前向き・後ろ向きアルゴリズムについてのメモ
8章で解説されている前向きアルゴリズムに関するメモです. 私が勉強していてつまずいたところを,本文に即する形で補足します.
求めたいのは,サイコロの目の系列 が得られる確率
です.
この確率は潜在変数を用いて
と表すことができます.
\begin{align} \sum_{ \mathbf{s} } \end{align}
は一見普通の和に見えますが,実は
\begin{align} \sum_{ \mathbf{s} } = \sum_{s_1} \sum_{s_2} \sum_{s_3} \dots \sum_{s_n } \end{align}
という恐ろしい形の和です.
\begin{align} P( \mathbf{x}, \mathbf{s}) = \Pi_{ \mathbf{s} } a(s_{t-1}, s_{t}) b(s_t, x_t) \end{align}
この同時確率から $ \mathbf{x} $ のみに関する確率を得るためには,上で述べた恐ろしい $ \mathbf{s} $ に関する周辺化を行う必要があり, $ s_n $ の $ n $ が大きくなると現実的ではありません($ O(2nc^{n}) $ になります).
ここで,
\begin{align} P( \mathbf{x}, s_t = w_i ) \end{align}
について考えてみましょう.
\begin{align} P( \mathbf{x}, s_t = w_i ) &= P( x_1 x_2 \dots x_t, s_t = w_i ) P( x_{t+1} x_{t+2} \dots x_{n} | x_1 x_2 \dots x_t, s_t = w_i) \\ &= P(x_1 x_2 \dots x_t, s_t = w_i ) P( x_{t+1} x_{t+2} \dots x{n} | s_t = w_i ) \end{align}
最後の式で,2つ目の確率の条件の部分から $ x_1 x_2 \dots x_t $ が消えていることに気づくと思います.
この消去は条件付き独立の定義によって行われています.
問題文の条件に従ってグラフィカルモデルを書いてみると, $ x_n $ は $ x_1 \dots x_{n-1} $ の値とは独立であることがわかります.
ここで,
\begin{align} \alpha_t (i) = P(x_1 x_2 \dots x_t, s_t = w_i) \end{align}
とします.
$ \alpha_n (i) $ を $ \alpha_{n-1} (i) $を用いて表すことができないか考えてみます.
(唐突感がありますが, $ t = n-1 $とおいて考えてみたらこうなりました)
\begin{align} \alpha_n (i) = \left[ \sum_{j=1}^{c} \alpha_{n-1} (j) a(s_{n-1}, s_n) \right] b(s_{n}, x_{n}) \end{align}
ただし.$ t = 1 $のときは $ \alpha_{1} (i) = \rho_i b(w_i, x_1) $ とします.
得られた確率をよく見ると, $ \alpha_{n} (i) $ は $ P( \mathbf{x}, s_t = w_i ) $であることに気づきます.
つまり,これを $ i $ について周辺化すれば求めたい確率 $ P( \mathbf{x} ) $ を得ることができます.
よって,
\begin{align} P( \mathbf{x} ) = \sum_{i = 1}^c \alpha_{n} (i) \end{align}
となります.
おつかれさまでした.
Nonparametric-Bayesian-Word-Sense-Induction
- conference: TextGraphs-6 (conference? journal?)
- authors: Xuchen Yao, Benjamin Van Durme
概要
語義推定タスクに対して,ノンパラメトリックな手法を適用する研究.
前提知識の中で知らなかったこととしては,WSI(word sense induction)とWSD(word sense disambiguous)は違うということ.
後者はあらかじめ決められた語義集合の中で議論を行うが前者は特定の語義集合を仮定していない.
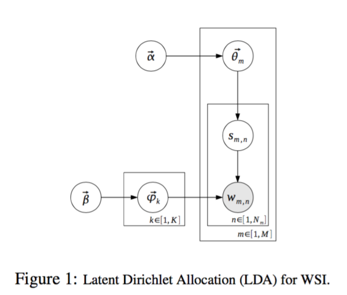
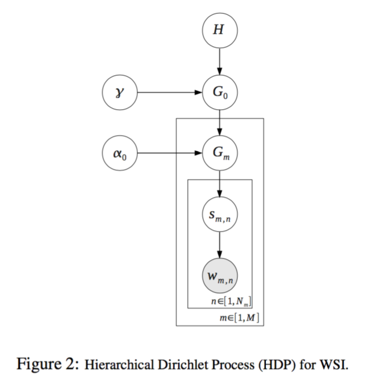
階層ディリクレ過程(以後HDP)を用いて推定した語義と,既存研究で行なわれている潜在的ディリクレ配分法(以後LDA)によって推定した語義の比較を行う.
あらかじめ語義の種類がわかっているデータセットに対してHDPを用いて語義の推定を行い,推定された語義の種類数が実際の語義の種類数とどの程度近いかを確認することで,HDPがこのタスクに対して有効かどうかがわかる.
手法
Feature
Context-Windowを設けてBag-of-Wordsで表現したベクトルを使う.
アーキテクチャ
| LDA | HDP |
|---|---|
 |
 |
 |
 |
| トピック数が固定 | トピック数が可変 |
実験
モデル
- LDAを使ったBrody+ [2009]のモデル
- HDPを使ったモデル(提案手法)
なお,両方とも文脈窓幅は10で固定.
構文的な情報とかを使った複雑なモデルは対してパフォーマンスの向上に寄与しなかったから普通のLDAを使ったヨみたいなことが書いてある気がする...
テスト
名詞の語義を推定する.
SemEval-2007データセットのWSIデータ(Wall Street Journalのデータから作成されたデータ)を使う.
評価方法
データをMapping, Dev, Testの3つに分割して,Mappingのデータで語義の割り当て(単語に対してCluster IDが割り当てられる)を行う.
そのあと,Cluster IDと語義の対応付けを行う.
学習
語義を推定する名詞の数は35.
モデルの学習に使うデータは2種類(in-domainとout-of-domainとあるが,これはなんだろう(特定のドメインのデータかそうじゃないか?).)
Wall Street Journal(以後WSJ): in-domain
British National Corpus(以後BNC): out-of-domain
実験結果
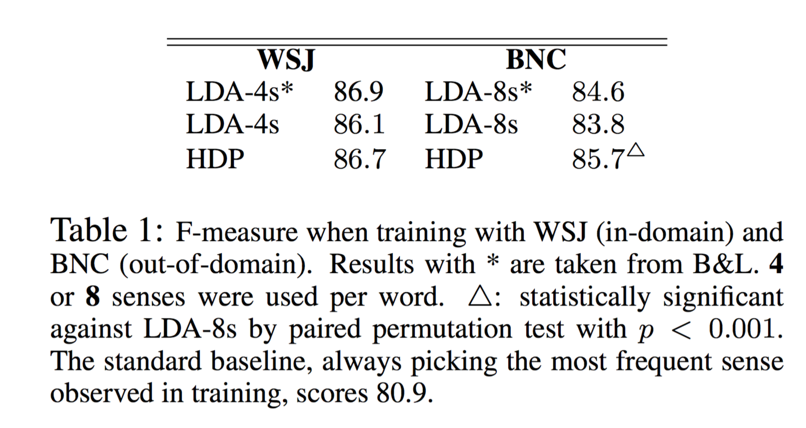
WSJ(in-domainなデータ)では,B&Lの手法と同等のパフォーマンスであったが,BNC(out-of-domainなデータ)に対しては提案手法の方が有意に良いパフォーマンスを発揮した.これは,語義が多いデータに対しても,提案手法であれば対応できることを示している.
結論
「語義推定をLDAを用いて行った研究は存在するが,LDAは語義の種類の数をあらかじめ決定する必要がある.そこで,我々はデータから語義の種類の数も学習するHDPを用いたモデルを提案し,LDAを用いたモデルとの比較を行った.結果として,HDPとLDAはほぼ同等のパフォーマンスが得られることがわかった.」
本文中の画像は原論文より抜粋している.
True Knowledge: Open-Domain Question Answering Using Structured Knowledge and Inference
- journal: AI Magazine2010 (published by AAAI)
- author: William Tunstall-Peadoe
質問応答システムTrue Knowledgeの論文.Eviっていうとわかる人が多いんだろうか(私は恥ずかしながら両方知らなかった). 著者はTrue KnowledgeのfounderのWilliam氏.
概要
True Knowledgeの全体像を説明している.昔ながらのシステム構想で作られた本格的な質問応答システム(だと思う). いくつかのコンポーネントをAPIとして本体から切り出している(もはや本体とはな状況だが)のもウリの1つらしい.
知識表現
KBでは様々な知識をグラフ構造を用いて表現している. また,ちゃんと説明できる自信がないので気になる人は論文を読んでいただきたいのだが,知識の表現にオントロジー的アプローチを採用している(論文のfig4).
推論
KBを構築するにあたって,あらゆる知識をKBに格納していくとKBが非常に重たくなってしまう.そのため,基本的な知識によって推論することが可能な知識の一部はKBには格納されておらず,推論という枠組みで動的に生成される. 例えば,
\begin{align} \mbox{(Big Ben is in London.)}, \mbox{(London is in UK.)} \to \mbox{Big Ben is in UK.} \end{align}
といった具合.推論をどの程度行うかというのはシステムによって異なっていて,システムによってはパフォーマンスを上げるために上記のような知識もすべてKBに格納していることもあるそうだ(推論にはある程度時間がかかる).
推論は,generatorと呼ばれる規則の集合を用いて行われる.True Knowledgeでは現在1500程度の推論規則が使われているらしい.
また,Computationと呼ばれる推論もサポートしている(例えば,1863年の3日目は何曜日?といった質問に対して金曜日と解答する際に行われる演算機構). こちらはSmart Generatorと呼ばれ,別のWebサービスとして独立しているらしい.
翻訳
ユーザから送られてくる質問文を知識ベースに対して投入するクエリに変換するコンポーネント. テンプレートの集合によって実装しているとあるので書き換え規則とアライメントを使った手法なのかな.
知識獲得
知識資源としては,いろいろな構造化データベース(is 何)はKBにインポートしていて,異なる分野をまたぐ知識を提供するためにFreebaseも使っている.
また,データとしてはWikipediaのデータとユーザが追加するデータも利用している.フィードバックを活用できる枠組みが確立しているということは検索エンジンや質問応答システムを構築するにあたって非常に良いことだろうなぁと思った.
NLP技術を活用した知識獲得も同様に行っている(Sentence extraction, Simplification, Translation, Bootstraping(?)).
とここまで読んだところで,手法に関する記載はあまりない印象を受けたので打ち切り. こういう動かせるレベルのシステムを作れるのは本当にすごいなぁ.