Nonparametric-Bayesian-Word-Sense-Induction
- conference: TextGraphs-6 (conference? journal?)
- authors: Xuchen Yao, Benjamin Van Durme
概要
語義推定タスクに対して,ノンパラメトリックな手法を適用する研究.
前提知識の中で知らなかったこととしては,WSI(word sense induction)とWSD(word sense disambiguous)は違うということ.
後者はあらかじめ決められた語義集合の中で議論を行うが前者は特定の語義集合を仮定していない.
階層ディリクレ過程(以後HDP)を用いて推定した語義と,既存研究で行なわれている潜在的ディリクレ配分法(以後LDA)によって推定した語義の比較を行う.
あらかじめ語義の種類がわかっているデータセットに対してHDPを用いて語義の推定を行い,推定された語義の種類数が実際の語義の種類数とどの程度近いかを確認することで,HDPがこのタスクに対して有効かどうかがわかる.
手法
Feature
Context-Windowを設けてBag-of-Wordsで表現したベクトルを使う.
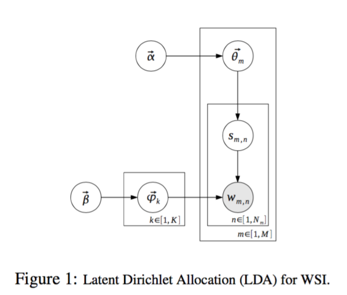
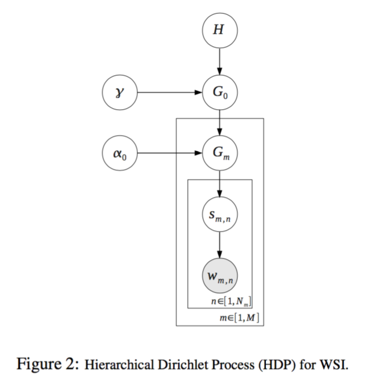
アーキテクチャ
| LDA | HDP |
|---|---|
 |
 |
 |
 |
| トピック数が固定 | トピック数が可変 |
実験
モデル
- LDAを使ったBrody+ [2009]のモデル
- HDPを使ったモデル(提案手法)
なお,両方とも文脈窓幅は10で固定.
構文的な情報とかを使った複雑なモデルは対してパフォーマンスの向上に寄与しなかったから普通のLDAを使ったヨみたいなことが書いてある気がする...
テスト
名詞の語義を推定する.
SemEval-2007データセットのWSIデータ(Wall Street Journalのデータから作成されたデータ)を使う.
評価方法
データをMapping, Dev, Testの3つに分割して,Mappingのデータで語義の割り当て(単語に対してCluster IDが割り当てられる)を行う.
そのあと,Cluster IDと語義の対応付けを行う.
学習
語義を推定する名詞の数は35.
モデルの学習に使うデータは2種類(in-domainとout-of-domainとあるが,これはなんだろう(特定のドメインのデータかそうじゃないか?).)
Wall Street Journal(以後WSJ): in-domain
British National Corpus(以後BNC): out-of-domain
実験結果
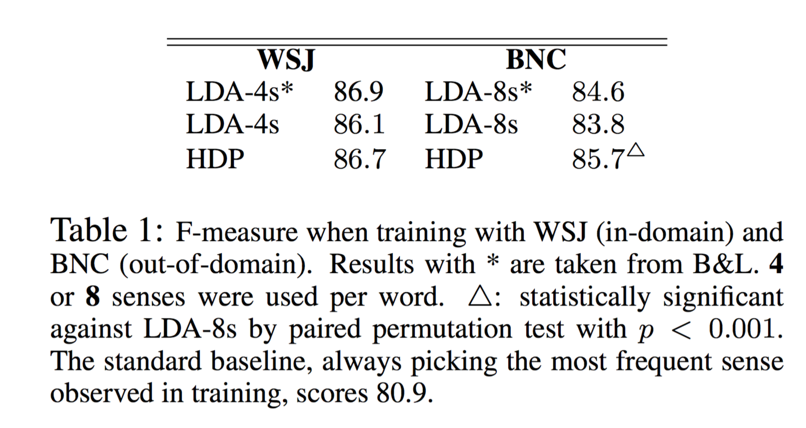
WSJ(in-domainなデータ)では,B&Lの手法と同等のパフォーマンスであったが,BNC(out-of-domainなデータ)に対しては提案手法の方が有意に良いパフォーマンスを発揮した.これは,語義が多いデータに対しても,提案手法であれば対応できることを示している.
結論
「語義推定をLDAを用いて行った研究は存在するが,LDAは語義の種類の数をあらかじめ決定する必要がある.そこで,我々はデータから語義の種類の数も学習するHDPを用いたモデルを提案し,LDAを用いたモデルとの比較を行った.結果として,HDPとLDAはほぼ同等のパフォーマンスが得られることがわかった.」
本文中の画像は原論文より抜粋している.