Research and reviews in question answering system
走り書きです.
- conference CIMTA 2013
- Sanjay and Vaishali
概要
QAのサーベイ. QAは現在のクエリを投入したら適合文書のリストが渡されて,そこから正確な情報をクエリ投入者が探すというパラダイムを超える可能性を持っている.
QAシステムは時間をかけて大変進歩してきたが,まだ幾つかの挑戦的な課題を残している.
- 自然文の質問を理解すること
- 質問タイプの分類
- 適切なクエリ化
- 曖昧性解消
- 意味的類似語の検出
identification of temporal relationship in complex questions
QAシステムの3つのステップ
- 質問解析
- パージング
- 質問分類
- クエリ構築
- 文書解析
- 候補抽出
- 解答特定
解答解析
- 解答候補のランク付け
QAシステムの分類
Linguistic Approach
- tokenization and parsing
- 異なる分野では異なる文法が必要になるなど,可搬性に乏しい
- 適切なKBを作るのは時間がかかる
- knowledge information is organized in the form of production rules, logics, frames, templates(triple relations), ontologies and semantic networks
- tokenization and parsing
Statistical Approach
Pattern Matching Approach
Ling
データベースに問い合わせるための自然言語インターフェース
自然言語文をクエリにする
- BASEBALL
- LUNAR
DIALOG
- ELIZA
- GUS
これらの手法では,データを構造化データベースに格納するため,解答能力に制約がある.
これらの制約を許容して,構造化データベースから得られる情報をもとに推論を行うタイプの質問応答システムが現れた.
STARTはWEBを知識源としている.経験則的な情報を用いてWeb上の情報を知識ベースに格納する.
Rule
Auarc,Carqは経験則にもとづいて質問文中から質問のタイプを分類する語彙的,意味的なヒントを探す.
- who, what, which, where,...
- others
Statistical
Answer finding task(クエリに対応する解答を統計的に探す)に使ってみたところ,パフォーマンスはデータセットの語彙数に依存することがわかった.
IBMが作った質問応答システムでは,Okapi(BM25?)とTREC-9のQAコーパスを使ったクエリの拡張の2つを採用していた.
Statistical methodでは,クエリと文書,もしくは一文との類似度をどのように計算するかがキモになっていて,キーワードの類似度やクエリや文書の長さ,出現単語の語順の類似など,様々な尺度が考えられ適用されている.
Pattern Matching
「Where was Cricket World Cup 2012 held ?」という質問に対して,「where was
現在の質問応答システムの多くは上記のようなパターンをテキストから自動的に学習することが多い(言語学的な知識やオントロジー,言語資源(WordNetなど)を用いる複雑な手法は採用されない傾向がある).
あまり複雑な質問に応答することはできない(パターンが膨大になる)ため,小-中規模の比較的簡単かつ限られた質問をされるような場面で使いやすい.
Surface Pattern based
大量の正規表現を使って解答を抽出する.
正規表現を大量に作成するのは非常に手間のかかる作業であるが,それらによって抽出される解答は非常に精度が高い.
得られた解答の信頼度を定量的に示すためにsurface patternを用いる手法もある.それらは高精度かつ低再現度である.
Template based
slotを埋めていくアプローチ.slotを埋めるタイプの質問応答は音声系の研究で多いと指導教官に教えてもらった記憶がある.
新しいデータが入ってきたとき,新しいテンプレートを作らなくてはそのデータに対応することができない.
Summary
linguistic approachは限定的なドメインをスコープに持つときにきわめて良いパフォーマンスを発揮する. 知識ベースを人でで作るのは分野の専門家が必要であり,手間もかかる. 最近の研究では,Webを知識源とすることによって知識ベースを強化したりオープンドメイン質問応答をしようという試みがある.
Statistical approachは充分な語彙数の大規模なデータ(= データ間が比較可能)が得られているときに良いパフォーマンスを発揮する. Statisticalなアプローチを取るときには,充分な訓練データがなければいけないが,一度適切に学習することができれば複雑な質問に対しても良い解答を生成することができる.
Pattern based approachは言語学的な分析をする代わりにテキストの特徴的な表現を活用する.Pattern basedな手法はその「浅さ」(表面情報しか加味しない点)ゆえに失敗することもあるが,Webをデータ源として活用するための効率的なテクニックでもある.Pattern basedな手法は,言語学的な情報への依存を減少させるだけでなく,不均質なデータをうまく扱える.だが,しばしばこの手法は意味的におかしい解釈や判断を行うことがある)(「浅さ」ゆえに).
これらの基本的なアプローチは,単体ではそれぞれに異なる制約がある.これらの手法を組み合わせることでより精度,再現率の良いシステムを構築する試みもあり,ASQAやIBM Watsonなどが有名.
結び
QAシステムを実装するにあたって,どの技術を用いるべきかは想定される問題のタイプにきわめて強く依存している. 複数のアプローチのハイブリッドが良い結果を出しているが,以前として基本的な手法の研究も重要であり続けるだろう.
Python文法詳解メモ
Python文法詳解という本がある. 読むととてもためになる.自分がおおと思ったものをメモしている.
気になったら実際に読んでみると良いと思います.上記のリンクはオライリーの商品詳解ページを指していますが,このリンクを経由して本書を購入することで私に金銭的な利益が発生することはないので安心してください.
適当な値を要素に持つ配列を作る
こうしてた
[1 for _ in range(N)]
こうできる
[1] * N
罠があります(前者で作るのかな). 後者の書き方でリストを作ると実行時間が劇的に短い.なんでかは考えてみてください.
算術演算
これは
a ** b % c
こっちのほうが高速
pow(a, b, c)
powって第三引数取れたんですね...
リストの展開
def spam(ham, egg): return (ham, egg) a = [1, 2] spam(*a)
辞書の展開
def spam(ham, egg): return (ham, egg) a = {'ham': 1, 'egg': 2} spam(**a)
ちなみに辞書を展開して変数にする(?)ので,キーは文字列でなければなりません(1 = 2みたいなことになってしまう).
要素の分解
a, b, *c = list(range(10))
右辺の要素の数が足りないとき,cは空のリストになる(ただし,a, bは値がないといけないので,以下はエラーになる.
a, b, *c = list(range(1)) #=> Traceback (most recent call last): # File "<stdin>", line 1, in <module> # ValueError: not enough values to unpack (expected at least 2, got 1)
shallow copyとdeep copy
>>> a = [1,2,3] >>> b = a >>> a.append(1) >>> a [1, 2, 3, 1] >>> b [1, 2, 3, 1]
>>> >>> a = [1,2,3] >>> b = a.copy() >>> a.append(1) >>> b [1, 2, 3] >>> a [1, 2, 3, 1]
よく見ると新しくオブジェクト作ってるやつ
>>> a = 1 >>> b = a >>> a += 1 >>> b 1
list.extend(iterable)
>>> a = [1,2,3]
>>> a.extend([1,2,3])
>>> a
[1, 2, 3, 1, 2, 3]
>>> a.extend('spam')
>>> a
[1, 2, 3, 1, 2, 3, 's', 'p', 'a', 'm']
>>>
リストの末尾にイテラブルオブジェクトのすべての要素を追加する.
list.sort(key=int)
>>> a = ['1', '10', '2', 3] >>> a.sort(key=int) >>> a ['1', '2', 3, '10']
なにこれすごい.
str.center(w)
>>> 'a'.center(10) ' a ' >>> 'a'.center(10, '*') '****a*****' >>>
プログラミング演習でつかえそう(内輪ネタ).
辞書内包
>>> {x+y:1 for x in 'abc'
for y in '123'}
{'a3': 1, 'c2': 1, 'c1': 1, 'c3': 1, 'a2': 1, 'b3': 1, 'b2': 1, 'a1': 1, 'b1': 1}
>>>
集合内包
{i for i in range(10)}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>>
set(i for i in range(10))って書いてた.
そういえば,set([i for i in range(10)])って書かなくて良いのも最近知りました.
例外の送出
raise ValueError('不正な値です')
print('不正な値です')ってやってた.
関数アノテーション
>>> def spam(ham: "ハムの枚数") -> int: ... return ham >>> spam(2)
きちんと書くとIDEが良い感じにしてくれるらしい(伝聞).
ラムダ式
>>> f = lambda x, y, z: 1 >>> f(1, 2, 3) 1 >>>
続パタの前向き・後ろ向きアルゴリズムについてのメモ
8章で解説されている前向きアルゴリズムに関するメモです. 私が勉強していてつまずいたところを,本文に即する形で補足します.
求めたいのは,サイコロの目の系列 が得られる確率
です.
この確率は潜在変数を用いて
と表すことができます.
\begin{align} \sum_{ \mathbf{s} } \end{align}
は一見普通の和に見えますが,実は
\begin{align} \sum_{ \mathbf{s} } = \sum_{s_1} \sum_{s_2} \sum_{s_3} \dots \sum_{s_n } \end{align}
という恐ろしい形の和です.
\begin{align} P( \mathbf{x}, \mathbf{s}) = \Pi_{ \mathbf{s} } a(s_{t-1}, s_{t}) b(s_t, x_t) \end{align}
この同時確率から $ \mathbf{x} $ のみに関する確率を得るためには,上で述べた恐ろしい $ \mathbf{s} $ に関する周辺化を行う必要があり, $ s_n $ の $ n $ が大きくなると現実的ではありません($ O(2nc^{n}) $ になります).
ここで,
\begin{align} P( \mathbf{x}, s_t = w_i ) \end{align}
について考えてみましょう.
\begin{align} P( \mathbf{x}, s_t = w_i ) &= P( x_1 x_2 \dots x_t, s_t = w_i ) P( x_{t+1} x_{t+2} \dots x_{n} | x_1 x_2 \dots x_t, s_t = w_i) \\ &= P(x_1 x_2 \dots x_t, s_t = w_i ) P( x_{t+1} x_{t+2} \dots x{n} | s_t = w_i ) \end{align}
最後の式で,2つ目の確率の条件の部分から $ x_1 x_2 \dots x_t $ が消えていることに気づくと思います.
この消去は条件付き独立の定義によって行われています.
問題文の条件に従ってグラフィカルモデルを書いてみると, $ x_n $ は $ x_1 \dots x_{n-1} $ の値とは独立であることがわかります.
ここで,
\begin{align} \alpha_t (i) = P(x_1 x_2 \dots x_t, s_t = w_i) \end{align}
とします.
$ \alpha_n (i) $ を $ \alpha_{n-1} (i) $を用いて表すことができないか考えてみます.
(唐突感がありますが, $ t = n-1 $とおいて考えてみたらこうなりました)
\begin{align} \alpha_n (i) = \left[ \sum_{j=1}^{c} \alpha_{n-1} (j) a(s_{n-1}, s_n) \right] b(s_{n}, x_{n}) \end{align}
ただし.$ t = 1 $のときは $ \alpha_{1} (i) = \rho_i b(w_i, x_1) $ とします.
得られた確率をよく見ると, $ \alpha_{n} (i) $ は $ P( \mathbf{x}, s_t = w_i ) $であることに気づきます.
つまり,これを $ i $ について周辺化すれば求めたい確率 $ P( \mathbf{x} ) $ を得ることができます.
よって,
\begin{align} P( \mathbf{x} ) = \sum_{i = 1}^c \alpha_{n} (i) \end{align}
となります.
おつかれさまでした.
Nonparametric-Bayesian-Word-Sense-Induction
- conference: TextGraphs-6 (conference? journal?)
- authors: Xuchen Yao, Benjamin Van Durme
概要
語義推定タスクに対して,ノンパラメトリックな手法を適用する研究.
前提知識の中で知らなかったこととしては,WSI(word sense induction)とWSD(word sense disambiguous)は違うということ.
後者はあらかじめ決められた語義集合の中で議論を行うが前者は特定の語義集合を仮定していない.
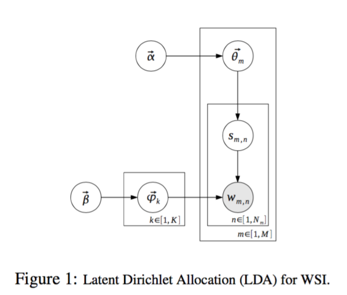
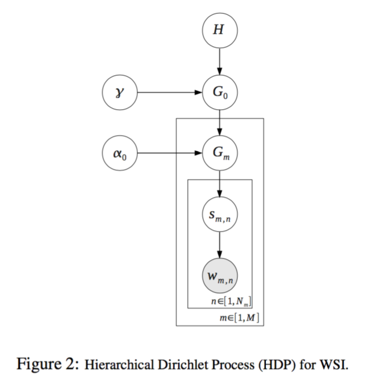
階層ディリクレ過程(以後HDP)を用いて推定した語義と,既存研究で行なわれている潜在的ディリクレ配分法(以後LDA)によって推定した語義の比較を行う.
あらかじめ語義の種類がわかっているデータセットに対してHDPを用いて語義の推定を行い,推定された語義の種類数が実際の語義の種類数とどの程度近いかを確認することで,HDPがこのタスクに対して有効かどうかがわかる.
手法
Feature
Context-Windowを設けてBag-of-Wordsで表現したベクトルを使う.
アーキテクチャ
| LDA | HDP |
|---|---|
 |
 |
 |
 |
| トピック数が固定 | トピック数が可変 |
実験
モデル
- LDAを使ったBrody+ [2009]のモデル
- HDPを使ったモデル(提案手法)
なお,両方とも文脈窓幅は10で固定.
構文的な情報とかを使った複雑なモデルは対してパフォーマンスの向上に寄与しなかったから普通のLDAを使ったヨみたいなことが書いてある気がする...
テスト
名詞の語義を推定する.
SemEval-2007データセットのWSIデータ(Wall Street Journalのデータから作成されたデータ)を使う.
評価方法
データをMapping, Dev, Testの3つに分割して,Mappingのデータで語義の割り当て(単語に対してCluster IDが割り当てられる)を行う.
そのあと,Cluster IDと語義の対応付けを行う.
学習
語義を推定する名詞の数は35.
モデルの学習に使うデータは2種類(in-domainとout-of-domainとあるが,これはなんだろう(特定のドメインのデータかそうじゃないか?).)
Wall Street Journal(以後WSJ): in-domain
British National Corpus(以後BNC): out-of-domain
実験結果
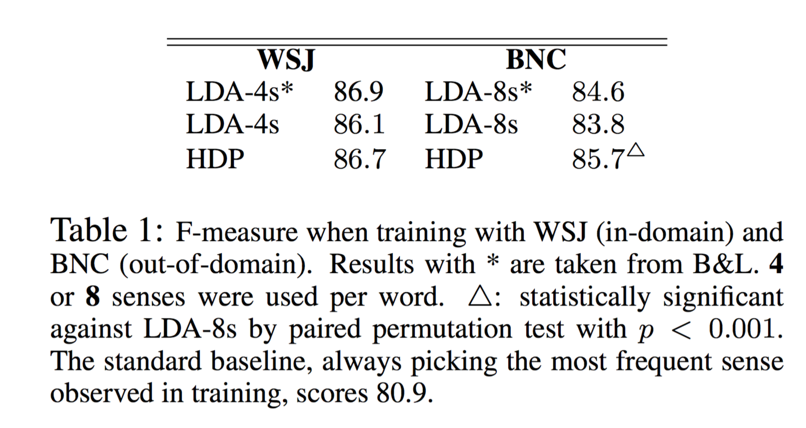
WSJ(in-domainなデータ)では,B&Lの手法と同等のパフォーマンスであったが,BNC(out-of-domainなデータ)に対しては提案手法の方が有意に良いパフォーマンスを発揮した.これは,語義が多いデータに対しても,提案手法であれば対応できることを示している.
結論
「語義推定をLDAを用いて行った研究は存在するが,LDAは語義の種類の数をあらかじめ決定する必要がある.そこで,我々はデータから語義の種類の数も学習するHDPを用いたモデルを提案し,LDAを用いたモデルとの比較を行った.結果として,HDPとLDAはほぼ同等のパフォーマンスが得られることがわかった.」
本文中の画像は原論文より抜粋している.
True Knowledge: Open-Domain Question Answering Using Structured Knowledge and Inference
- journal: AI Magazine2010 (published by AAAI)
- author: William Tunstall-Peadoe
質問応答システムTrue Knowledgeの論文.Eviっていうとわかる人が多いんだろうか(私は恥ずかしながら両方知らなかった). 著者はTrue KnowledgeのfounderのWilliam氏.
概要
True Knowledgeの全体像を説明している.昔ながらのシステム構想で作られた本格的な質問応答システム(だと思う). いくつかのコンポーネントをAPIとして本体から切り出している(もはや本体とはな状況だが)のもウリの1つらしい.
知識表現
KBでは様々な知識をグラフ構造を用いて表現している. また,ちゃんと説明できる自信がないので気になる人は論文を読んでいただきたいのだが,知識の表現にオントロジー的アプローチを採用している(論文のfig4).
推論
KBを構築するにあたって,あらゆる知識をKBに格納していくとKBが非常に重たくなってしまう.そのため,基本的な知識によって推論することが可能な知識の一部はKBには格納されておらず,推論という枠組みで動的に生成される. 例えば,
\begin{align} \mbox{(Big Ben is in London.)}, \mbox{(London is in UK.)} \to \mbox{Big Ben is in UK.} \end{align}
といった具合.推論をどの程度行うかというのはシステムによって異なっていて,システムによってはパフォーマンスを上げるために上記のような知識もすべてKBに格納していることもあるそうだ(推論にはある程度時間がかかる).
推論は,generatorと呼ばれる規則の集合を用いて行われる.True Knowledgeでは現在1500程度の推論規則が使われているらしい.
また,Computationと呼ばれる推論もサポートしている(例えば,1863年の3日目は何曜日?といった質問に対して金曜日と解答する際に行われる演算機構). こちらはSmart Generatorと呼ばれ,別のWebサービスとして独立しているらしい.
翻訳
ユーザから送られてくる質問文を知識ベースに対して投入するクエリに変換するコンポーネント. テンプレートの集合によって実装しているとあるので書き換え規則とアライメントを使った手法なのかな.
知識獲得
知識資源としては,いろいろな構造化データベース(is 何)はKBにインポートしていて,異なる分野をまたぐ知識を提供するためにFreebaseも使っている.
また,データとしてはWikipediaのデータとユーザが追加するデータも利用している.フィードバックを活用できる枠組みが確立しているということは検索エンジンや質問応答システムを構築するにあたって非常に良いことだろうなぁと思った.
NLP技術を活用した知識獲得も同様に行っている(Sentence extraction, Simplification, Translation, Bootstraping(?)).
とここまで読んだところで,手法に関する記載はあまりない印象を受けたので打ち切り. こういう動かせるレベルのシステムを作れるのは本当にすごいなぁ.
Sentense-similarity-learning-by-lexical-decomposition-and-composition
- publish: arXiv
- author: Zhiguo Wang, Haitao Mi, Abraham Ittycheriah
概要
QAでCNNな研究.現在のWikiQAとQASentのstate-of-the-art (ACL Anthology wiki調べ, 2016/03/16).
アブストで「今までの文章類似度を計算する手法は似ている部分だけ着目していて,似ていない部分は無視しているが,似ていない部分の情報も重要だよ」みたいなことを言っていてなるほど確かにと思った.
まず,著者は既存の文章類似度の計算の3つの問題点の指摘から始める.
意味的に類似しているが,異なる語彙が用いられている場合に正確に類似度を計算できない
- Milkov+ (2013)の研究を例としてあげている.論文中でembeddingの手法についての詳しい言及がない(気がする)ので,word2vecを単語ベクトルを獲得するために使っているのかなと思った.
単語レベルではなく,フレーズレベル,構文レベルでも類似度を計算しなければいけない
- "not related"は単語に分割すべきではなく,フレーズとしてみれば"irrelevant"と似た表現とみなすことができる.
「類似している」という情報ではなく,「類似していない」という情報も活用しなければならない
これらを踏まえ (これらの問題に対処して) モデルを設計する.
手法
- 単語を低次元のベクトルで表現する
- すべての単語について,semantic matching vectorを計算する(よく分からない)
- semantic matching vectorを用いて,単語ベクトルをsimilar componentsとdissimilar componentの2つに分解する(Decompose)
- CNNを使って1つの特徴空間に射影する(Compose)
- 類似度はsumをとってsigmoid関数を適用するだけ
何回か読んだけどsemantic matching vectorがなんなのかよく分からない(代表ベクトルみたいなもの?).
semantic matching
we need to check whether each semantic unit in one sentence is covered by the other sentence, or vice versa.
包含関係を調べる必要がある."irrelevant"という1つの単語が"not related"というフレーズでカバーされていることを知る必要がある.どうするかというと,
\begin{align} \hat{s_i} &=& f_{match} (s_i, T) & \forall s_i \in S \\ \hat{t_i} &=& f_{match} (t_j, S) & \forall t_j \in T \end{align}
とするらしい(よくわかりません).
第3章で $$ f_{match} (s_i, T) $$についてはより詳細な定義が述べられている. 文書Sのサイズ x 文書Tのサイズの行列 $$ A $$ の $$i, j$$要素を
\begin{align} a_{i,j} = \frac{s_iT t_j}{|| s_i || \cdot || t_j ||} &&& \forall s_i \in S ,\forall t_j \in T \end{align}
として,
\begin{align} f_{match} (s_i, T) = \begin{cases} \frac{\sum_{j=0}^{n} a_{i,j} t_j}{\sum_{j=0}^{n} a_{i,j}} & global \\ \frac{\sum_{j=k-w}^{k+w} a_{i,j} t_j}{\sum_{j=k-w}^{k+w} a_{i,j}} & local-w \\ t_k & max \end{cases} \end{align}
誰かこれがなんなのか教えて下さい...
decomposition
$$ \hat{s_i} $$ と $$ \hat{t_j} $$は文章 $$ T $$ と $$ S $$に対する"意味的な適用範囲"(semantic coverage)と解釈できる.
\begin{align} \left[ s_i^{+}; s_i^{-} \right] = f_{decomp} (s_i, \hat{s_i}) \\ \left[ t_j^{+}; t_j^{-} \right] = f_{decomp} (t_j, \hat{t_j}) \end{align}
によって,単語ベクトルを類似部分と非類似部分の2つに分解する.
分解を行う関数はRigitな関数(なんて訳せば良いのかわからない,全か無をとる関数)か線形な関数,あと直行ベクトルを使う関数の三種類が挙げられている.
composition
\begin{align} \vec{S} = f_{comp} (S^{+}, S^{-}) \\ \vec{T} = f_{comp} (T^{+}, T^{-}) \end{align}
がっちゃんこ.
CNNによって,2種類のベクトルを1つのベクトル空間に射影する.
畳み込みのフィルターを $$ {w_o} (d × h)$$ とする( $$d$$ は単語ベクトルの次元, $$ h $$ はwindow size).
\begin{align} c_{o,i} = f( w_o * S_{\left[ i:i+h \right]}^{+} + w_o * S_{\left[ i:i+h \right]}^{-} + b_o) \end{align}
最適化にはAdam (Kingma+, 2014)を使っている.
評価実験
MAP (mean average precision) とMRR (mean reciprocal rank) を使って評価する.評価タスクは質問応答ではQASentとWikiQA.QASentはTREC QA trackで作られたデータで,QASentはWikipediaとBingに実際に入力されたクエリによって構成されている.言い換えではMSRP corpus (MSRP) で実験する(こちらはあまり追っていない).$$ d = 300 $$ (d = 単語次元)でembeddingを行う(ここでword2vecを使ったと書かれていた).
すごい (小学生並の感想).
Resource Analysis for Question Answering
なにこれ
質問応答システムを構築するとき,様々なリソースを知識源とする. この論文では,それらのリソースの比較を行っている. 質問応答初心者なので,どのリソースがどういう特徴を持っているか・またどのタイプの質問に対して有効かをよく知らなかったので読みました.
Gazatteer
Gazetteer(地名集).
「X(地名)の人口は?」,「Yの首都は?」と言った調子のファクトイド型の質問を扱うデータベース. CIA World Factbookは世界中の国々の地理的,政治的,経済的な特徴を収録している.
天文学に関する情報を収録しているAstronomyやアメリカの50州の情報を収録した50Statesなんかもある.
Gazatteerは常にデータを最新に保っているので,ある時点でのデータは別の時点のデータとは別物である可能性がある(=再現性のない実験結果が得られる可能性がある). また,「太陽との距離は?」といった質問のように,時期によって解答が異なる質問も時期によって異なる解答が得られる.
Gazatteerの特徴として,非常に精度の高い情報が収録されているという特徴がある(そのかわり再現率はあまり高くならない). TREC(質問文と解答文のデータセット)の質問のうち,Gazatteerの情報をそのまま利用できるタイプの問題に対しては非常に高い正解率を誇る.
WordNet
WordNetは概念辞書と呼ばれるもので,単語に関する説明を収録している.プリンストン大学で開発された. Web上インターフェースが公開されているので,試しに使ってみると良い. 日本版はないのって話だが,ある.こちらはNICT(国立研究開発法人情報通信研究機構)が提供している.
概念を整理し記述する,オントロジー.
Structured Data Sources
百科事典や辞書,その他のWeb上の資料は主に「Xって何?」,「Xって誰?」と言った定義を問うタイプの質問の解答を得るために用いられる. TRECで最も良い成績を収めたXuら(2003)のDefinitional System(日本語でなんて言えば良いんだろう?)では,WordNet(Miller et al., 1990)),the Marriam-Webstar dictionary,the Columbia Encyclopedia,Wikipedia,biography dictionary,そしてGoogle(これ資料って言うのか?)などの構造化・半構造化されたリソースを用いていた.
質問文からのN-gramをwikipediaやgoogleで検索するだけでもそこそこ解答が見つかることも多い(TRECの質問文での議論が論文中にあるので興味があったら読んでみてください).
Answer Type Coverage
自分の構築したシステムがどれくらい広範な質問に対応しているのかをテストしたいときには,JAVELINシステム(Nyberg et al., 2003)を使うと良い. 「viscosityって何?」とか「Lacanって誰?」とか「クレオパトラはどのように死んだ?」といった広範な知識を問う問題が収録されている.
Answer Typeは以下のように区分される.
- object
- lexicon
- definition
- person-bio
- process
- temporal
- numeric
- location
- proper
The Web as a Resource
Webはローカルに構築したコーパスよりも極めて巨大なので(web is orders of magnitude larger than local coporaってどういう意味だろう...),簡単な質問とそれに対する解答はより頻繁に出現する. そのため,正しい解答を得るためにとても有用である.
Web上のリソースはパターン獲得や文書文書検索,構造化データの抽出,そして解答の検証のために使われることが多い.
Web Documents
ローカルに構築したコーパスを探索するかわりに,Web上の資料を探索して解答を見つけることを試みる質問応答システムも存在する(Xu et al., 2003::たぶんStructured Data Sourceの章で言及した研究).
検索エンジンに対して質問文をtokenizeしたものをそのまま投げつける実験してみたら結構精度よかったみたいなことがその後に書かれています(google apiの話していたので読み飛ばした).
Web Based Query Expansion
擬似適合フィードバックとかみたいな,クエリを拡張する手法もあるよーって話をしている.
まとめ
QAに使えそうなリソースを紹介してもらいました. 手法自体は当時からかなり色々変わっているけれど,データの重要性は変わっていないと思うので,調べてみる価値はあったと思っている.